Growing Images from Text with Neural Cellular Automata
Code: github.com/mgoldfield/nca-clip
Goal
Can a tiny neural network (~8K parameters), operating with purely local rules on a grid of cells, learn to grow recognizable images from a text prompt?
The idea: combine Neural Cellular Automata (NCA) with CLIP as a training signal. An NCA is a learned update rule where each cell sees only its 3x3 neighborhood. Starting from a single pixel seed, cells divide and specialize, producing emergent global patterns from purely local interactions — like biological morphogenesis. CLIP provides a bridge between text and images, letting us optimize the NCA's update rule so the grown pattern matches a text prompt.
If this worked, a model smaller than most JPEG images could grow arbitrary images from text, with the organic aesthetics of cellular self-organization.
How It Works
The NCA has 16 channels per cell: 3 RGB (visible), 1 alpha (alive/dead), and 12 hidden (communication). Each step, every cell reads its 3x3 neighborhood through fixed perception filters (identity, Sobel-x, Sobel-y, Laplacian), processes the result through a small MLP (two 1x1 convolutions), and applies a residual update. Cells with no alive neighbor (alpha > 0.1) are zeroed out. Updates are stochastic (each cell updates with p=0.5) and bounded by tanh to prevent explosion.
CLIP loss guides training. We run the NCA forward for 32-64 steps from a single-pixel seed, extract the RGB channels, apply random augmentations (crop, rotation, color jitter), feed through a frozen CLIP ViT-B/32, and compute cosine similarity with the text prompt embedding. The NCA's weights are optimized to maximize this similarity.
Alpha loss provides an auxiliary growth incentive. Without it, the NCA has no reason to expand from the seed — CLIP can't evaluate what it can't see. We scale the growth reward proportionally to CLIP quality so the NCA can't game the system by flooding the grid with alive-but-blank cells.
What We Tried
Over three experiment pipelines (~130 experiments, ~60 hours of GPU time), we systematically explored:
- Alpha loss strategies: constant floor, proportional-to-CLIP, above-baseline gating
- Initialization: zero-init, random xavier, anti-diffusion (RGB sharpening), per-channel-type
- Grid sizes: 64x64, 128x128, 256x256
- Training length: 2K to 20K iterations with cosine LR annealing
- NCA steps per iteration: 8-16, 32-64, 64-128
- Augmentation: RandomResizedCrop vs simple resize
- Total Variation loss: penalizing pixel-level noise (tv=0, 0.01, 0.1)
- Signal channels: extra diffusion steps on hidden channels for faster long-range communication (a morphogen gradient analogy)
- Model capacity: 96 vs 192 hidden units, 2 vs 3 MLP layers
Results: Textures, Not Images
The NCA successfully learns to grow textures and color patterns associated with prompts, but never produces recognizable images.
Fire (best CLIP: -0.330)
Fire was our strongest result. The NCA grows a flame-like pattern from a single pixel — orange/blue coloring on a dark background, with the organic quality you'd expect from a cellular automaton. The growth process itself is compelling:
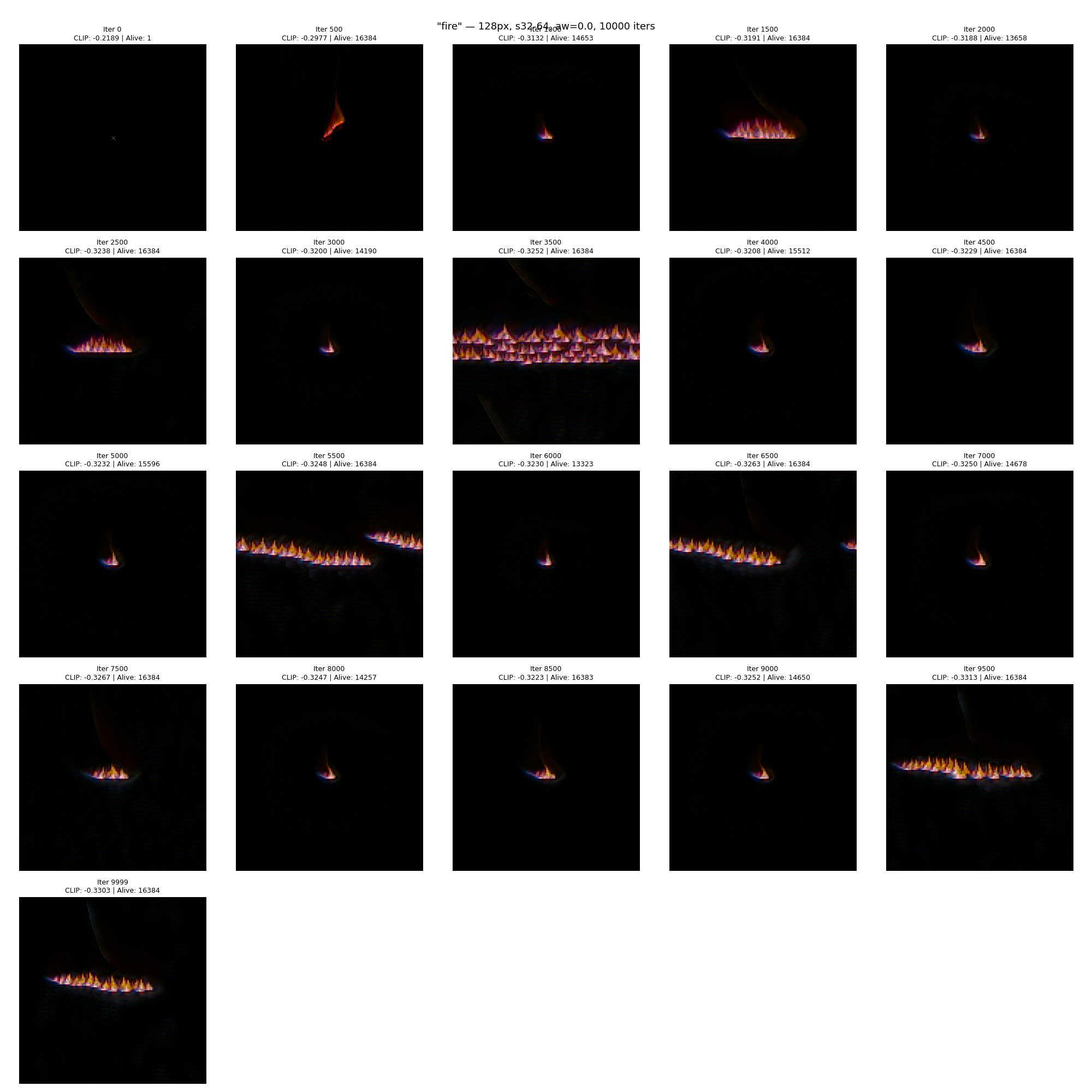 "fire" — 10K iterations, 128x128 grid. Each frame shows the NCA state at a different training checkpoint, grown from a single center pixel. CLIP loss improves from -0.22 (random) to -0.33.
"fire" — 10K iterations, 128x128 grid. Each frame shows the NCA state at a different training checkpoint, grown from a single center pixel. CLIP loss improves from -0.22 (random) to -0.33.
 Best fire result grown from seed after training.
Best fire result grown from seed after training.
Ocean (best CLIP: -0.350)
Ocean was the standout — a natural fit for NCA since waves are inherently a local-rule phenomenon. The teal/blue wave textures are convincing:
 "ocean" — 5K iterations, 128x128 grid.
"ocean" — 5K iterations, 128x128 grid.
Galaxy (best CLIP: -0.356)
Galaxy produced the highest CLIP score of any experiment, but only with a larger model (192 hidden units) and signal channels. It was completely dead (0 alive cells) in our earlier pipeline without these additions:
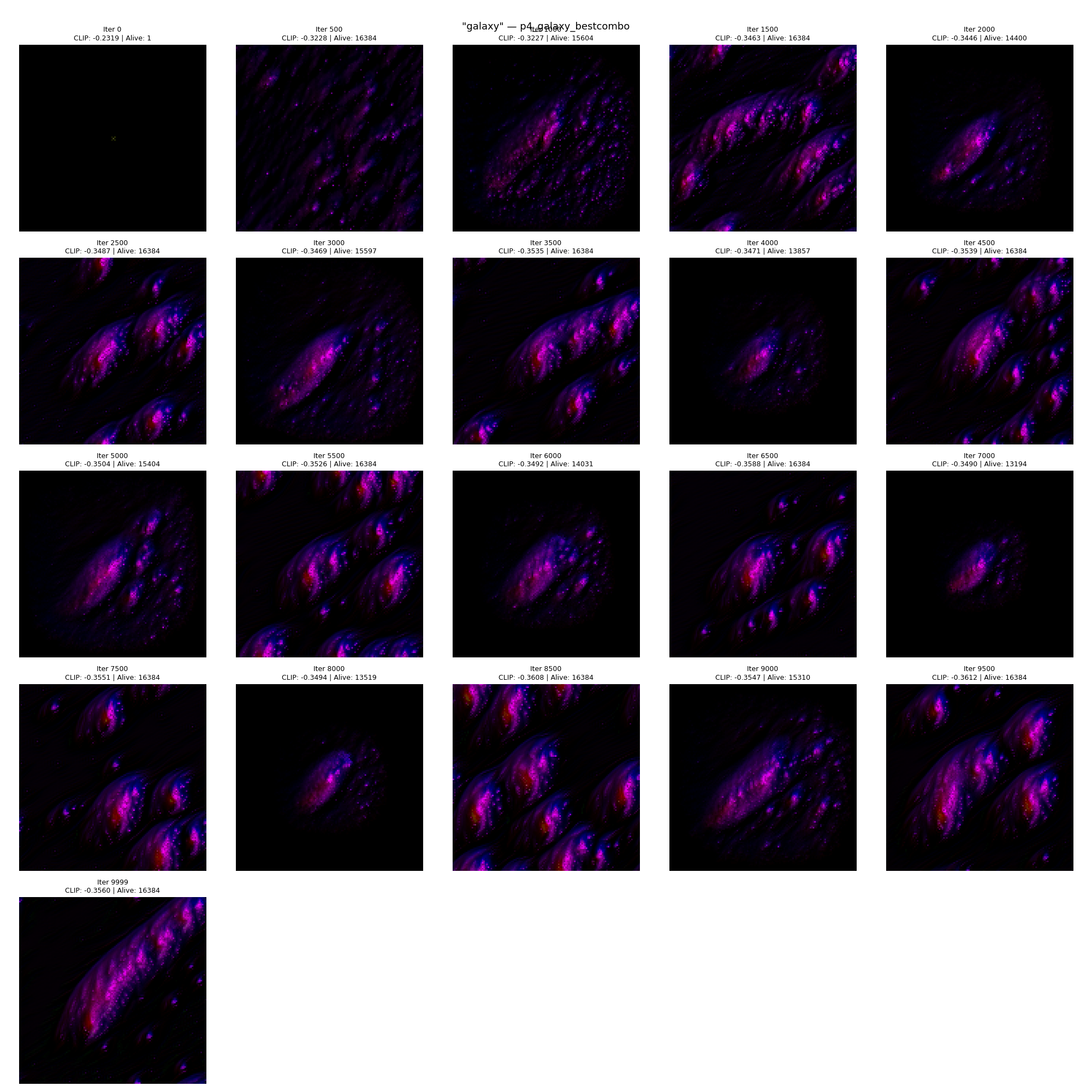 "galaxy" — 10K iterations, 192 hidden units, signal channels (4ch x 4 diffusion steps).
"galaxy" — 10K iterations, 192 hidden units, signal channels (4ch x 4 diffusion steps).
Cat (best CLIP: -0.333)
Cat illustrates the core limitation. Despite strong CLIP scores, the output is brown/green textured patterns — fur-like, perhaps, but not a cat:
 "cat" — the best cat result produces repeating textural patterns, not a recognizable cat shape. CLIP evaluates texture and color associations ("brown tabby pattern"), not structural layout.
"cat" — the best cat result produces repeating textural patterns, not a recognizable cat shape. CLIP evaluates texture and color associations ("brown tabby pattern"), not structural layout.
Best results gallery
 Top row: final training state (all cells alive). Bottom row: grown fresh from a single pixel seed after training. Fire and ocean produce recognizable textures. Cat and flower produce prompt-associated colors but no structure.
Top row: final training state (all cells alive). Bottom row: grown fresh from a single pixel seed after training. Fire and ocean produce recognizable textures. Cat and flower produce prompt-associated colors but no structure.
Why It Doesn't Work
The locality constraint
Each NCA cell sees only its 3x3 neighborhood. Information travels 1 pixel per step. In 64 steps, a signal from the center reaches ~64 pixels — not enough for global spatial coordination on a 128x128 grid. The NCA can produce locally coherent texture but has no mechanism to decide "the cat's eye goes here, the ear goes there."
We tried to fix this with signal channels — hidden channels that get extra diffusion steps per NCA step, acting like morphogen gradients that carry information faster across the grid. With a larger model (192 hidden units, 3 MLP layers), this improved cat from -0.309 to -0.333 CLIP, but the result was still texture, not structure:
 Phase 3: model capacity x signal channels. The 192h/3L configuration (bottom-right) was the only one to produce a strong cat result. But "strong" still means texture, not a cat.
Phase 3: model capacity x signal channels. The 192h/3L configuration (bottom-right) was the only one to produce a strong cat result. But "strong" still means texture, not a cat.
CLIP rewards texture, not structure
We ran a baseline experiment: optimize raw pixels directly with the same CLIP loss (no NCA). This removes the locality constraint entirely — every pixel is a free parameter.
![]() Direct pixel optimization with CLIP ViT-B/32, 2K iterations. Top row: with RandomResizedCrop. Bottom row: simple resize. CLIP scores are much better than any NCA result (-0.43 to -0.47), but the images are psychedelic adversarial noise.
Direct pixel optimization with CLIP ViT-B/32, 2K iterations. Top row: with RandomResizedCrop. Bottom row: simple resize. CLIP scores are much better than any NCA result (-0.43 to -0.47), but the images are psychedelic adversarial noise.
The pixel-optimized images achieve much lower CLIP loss than any NCA output, and you can make out vague shapes (a cat face, flower petals). But they're adversarial — high-frequency noise patterns that exploit shortcuts in CLIP's embedding space. Lower CLIP loss does not mean better images.
 Left columns: pixel-optimized results (with and without crop). Right column: best NCA results. The NCA produces more natural-looking output despite worse CLIP scores — its local rules act as an implicit regularizer against adversarial noise.
Left columns: pixel-optimized results (with and without crop). Right column: best NCA results. The NCA produces more natural-looking output despite worse CLIP scores — its local rules act as an implicit regularizer against adversarial noise.
This revealed the fundamental problem: CLIP is a discriminative model, not a generative one. It was trained to match images to text, not to define what images should look like. Optimizing directly against CLIP loss finds patterns that activate the right regions of embedding space through color and texture associations, not through structural resemblance to the prompt. This affects any generator, not just NCAs.
What Would Be Needed
The field converged on a solution to this problem: an image prior. A model trained on real images that constrains outputs to look like natural images. This is what diffusion models provide — CLIP (or T5) handles text steering, but the diffusion model's learned denoising process provides the "what does a real image look like" constraint.
For NCAs specifically, Score Distillation Sampling (SDS, from DreamFusion) could replace CLIP loss. Instead of asking "does this match the text?" (CLIP), SDS asks "does a pretrained image generator think this looks like a real image matching the text?" The NCA architecture stays the same — only the loss function changes. This is an unexplored combination: SDS has been used to train NeRFs and SVG renderers, but never NCAs.
What the NCA + CLIP Combination Is Actually Good At
The project didn't achieve text-to-image generation, but it produced genuinely interesting results:
- Emergent texture generation guided by text — fire, ocean, and galaxy produce compelling organic patterns
- Self-organizing growth from a single pixel, driven by nothing but local rules and a text prompt
- The growth process itself is aesthetically interesting — watching structure emerge from a seed is the appeal of cellular automata, and CLIP gives us a way to steer where that growth leads
 The NCA growing "fire" from a single center pixel. The growth dynamics — not just the final image — are the compelling output.
The NCA growing "fire" from a single center pixel. The growth dynamics — not just the final image — are the compelling output.
 "Ocean" growing from seed.
"Ocean" growing from seed.
 "Galaxy" growing from seed — the most visually striking result, enabled by signal channels and a larger model.
"Galaxy" growing from seed — the most visually striking result, enabled by signal channels and a larger model.
Technical Details
| Component | Details |
|---|---|
| NCA | 16 channels, 3x3 perception (identity + Sobel + Laplacian), 1x1 conv MLP, tanh bounding, alive masking |
| Model size | 7.8K params (base), up to ~30K with 192 hidden / 3 layers |
| Training | Adam, cosine LR 2e-3 to 1e-4 over 2K iters, 10K total iterations |
| CLIP | ViT-B/32, frozen, 8 random augmentations per image |
| Grid | 128x128, circular padding (toroidal) |
| Seed | Single center pixel, random RGB, alpha=1 |
| Growth | 32-64 NCA steps per training iteration |
| Experiments | ~130 runs across 3 pipelines, ~60 hours GPU time |
| Best CLIP scores | fire: -0.330, ocean: -0.350, galaxy: -0.356, cat: -0.333 |
References
- Mordvintsev et al. 2020 — Growing Neural Cellular Automata
- Radford et al. 2021 — Learning Transferable Visual Models From Natural Language Supervision (CLIP)
- Poole et al. 2022 — DreamFusion: Text-to-3D using 2D Diffusion
- Kalkhof et al. 2024 — Frequency-Time Diffusion with Neural Cellular Automata
- Mainakdeb/text-2-cellular-automata
- janzuiderveld/lightning-nca-clip